Wen-chang Lin
Wen-chang Lin

Wen-chang Lin

全盤了解人類基因體組成及其功能,是探討人類疾病起因及發展有效治療藥物不可或缺之基石。本研究室著重於開發生物資訊工具及資料庫分析人類基因體,並積極從事轉譯醫學應用,希望將所得研究成果用於改善癌症診斷與改良治療策略。除了建立數個人類同源基因研究之生物資訊資料庫應用於功能基因體。 先前開發了比較性基因辨識法CGI (Comparative Gene Identification)的生物資訊程式,而且,這種比較性基因體研究的方法的建立,有助於了解人類基因在演化及功能上的保留度及重要性,對於功能性基因體學研究有重要助益。對於更深入的同源基因比較基因研究,我們亦新發展了一套以基因轉譯單元為定位的基因資料庫。這套演算法可以校正某些標準參考基因 (RefSeq) 由於重複記錄不同差異性剪接合的異構體,而造成同源基因的混淆判別以及基因體資炓庫的重複性。此一新方法有助於研究學者建立一個更有效率及完整的同源基因資料。我們最近並加入了新功能研究連結,用更方便的使用者界面資訊來呈現Gene Ontology 的功能註解,以協助使用者了解同源基因的生物功能。在分析這些同源基因資料的時候,我們發現有約一成左右的人類基因在目前的標準人類基因體序列中有多重位置分佈的情形,推測這些基因可能是較年輕的複製區段的基因,由於它們的相似度有高達98%序列相似度,如何研究它們表現的差異便是一項挑戰性的課題。我們特別萃取出這些多重基因的序列,加以比對並尋找其中已知的SNP的位置,建立一套新的基因變異點資料庫dbSNV。再完成同源基因資訊之後,我們更進一步將同源基因內的內顯子(EXON)做細部的校正及比對,建立同源基因內顯子的資料庫。利用這些生物資訊分析資訊結合如dbEST的序列資料,我們發現基因的選擇剪接合複雜度與基因家族複製擴充之間有指標性關聯,並且和物種演化時間有一定關係。最近,我們發現有大量新穎基因共存在於蛋白質基因區間而形成重疊基因現象。最近分析及註解人類基因體序列,發現有高比例的重疊蛋白基因存在,以及利用大規模基因表現資料來研究重疊蛋白基因表現特徵。近來我們亦研究微型核醣核酸miRNA之生物資訊研究及癌症關聯。由於miRNA為非常小的RNA片段,因此由生物資訊演算法來辨別是比較有效率的研究方法 。我們建立一個新的miRNA辨識程式,並針對人類表現基因的序列進行辨識 ,以及其他物種 。由於辨識成效良好,我們進一步利用此miRNA辨識程式,對於二仟多個病毒基因體進行掃毒及辨識,進而找到數仟個新的miRNA分子。此一資料庫發表於NAR期刊,目前已有超過60個國家,數百個不同單位來使用以及瀏覽。 目前尋找及預測miRNA標的基因是在研究miRNA的生物功能中最重要,但也最困難的一環。我們更利用序列演化保留的特性,在五十個動物基因體中發現超過15000個以上高可信度的新miRNA基因 。我們更進一步利用這些資訊來研究miRNA在演化保留及基因叢集的重要資訊 。由於近來次世代定序平台 NGS 有重要突破,大規模定序資料普及,我們也開發利用次世代定序資料研究miRNA的表現,目前除了新工具開發 ,也分析了數個物種miRNA的次世代定序資料及miRNA分布,並建立新式的互動型資料庫 。我們也發現miRNA與人類胃癌有高度相關,並可以作為癌症分子標記,在癌症病患血液與尿液中可以偵測到miRNA的表現。最近我們研究人類蛋白質基因的轉錄訊息mRNA表現,利用GTEx的大數據資料建立專一表現的代表性轉錄訊息分子資料庫,並且對於其組織表現特異性進行視覺化研究,建立數個使用者友善的生物資訊資料庫。未來希望對於人類基因的功能性研究有所助益。
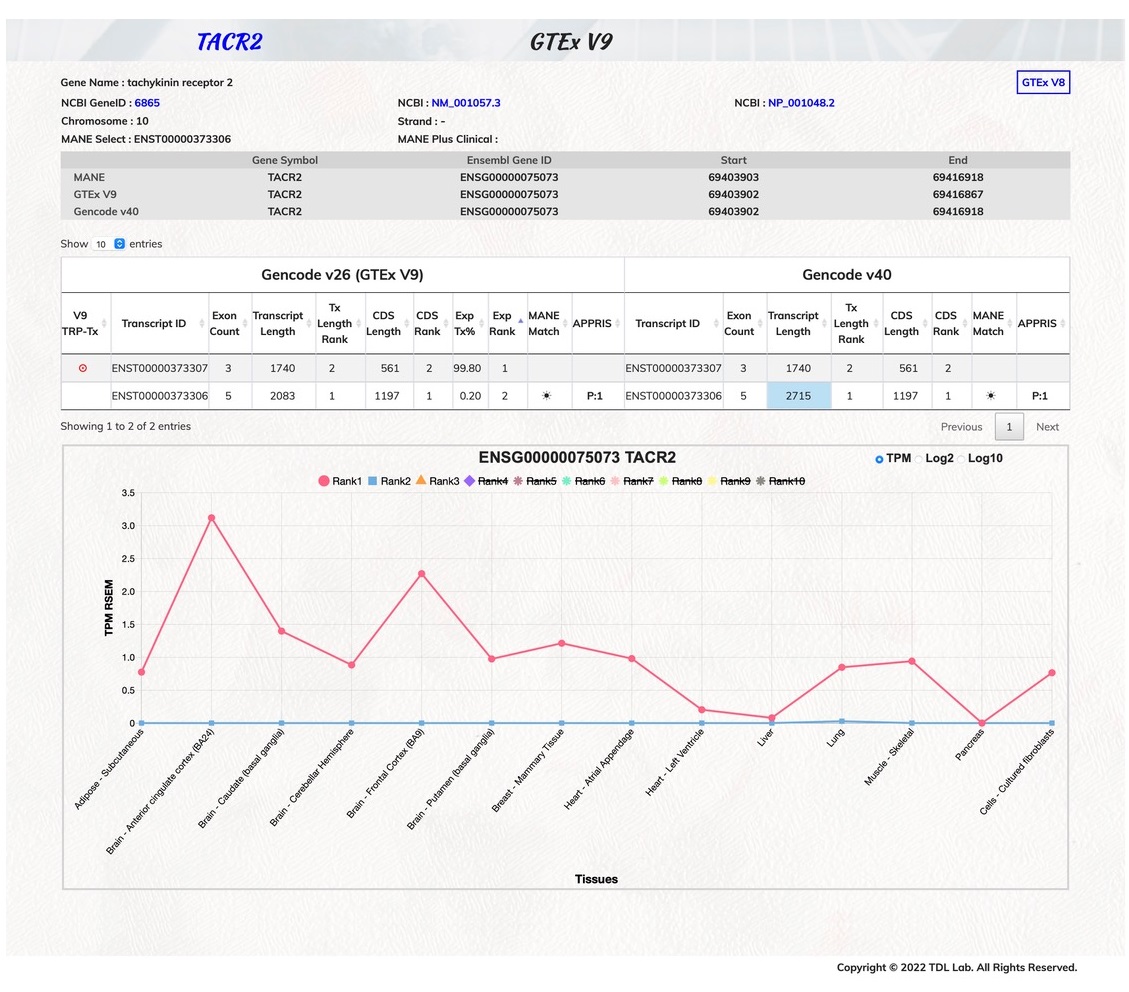
The long-term research goal of our laboratory is to utilize bioinformatic tools/databases in elucidating molecular and cellular aspects of functional transcription elements in human genome and their significance in oncogenesis and tumor progression. These functional transcription elements include traditional protein-coding genes and non-coding ones. Our research efforts are intended to elucidate functions and regulations of these transcription elements using bioinformatics data-mining and molecular experimental approaches. Previously, we have used the dbEST database for the discovery of novel human genes, identification of functional nucleotide polymorphisms (SNPs and InDels). Subsequently, we further discover and interrogate a new wobble-splicing mechanism at exon junctions that results in the generation of InDel variants in protein coding transcripts. In order to interrogate the functional aspects of these elements, we have developed gene oriented ortholog assignment and protein domain ortholog classification algorithms and databases. We have also emphasized on the discovery of non-coding regulatory microRNAs. Informatic pipelines are employed to discover and interrogate miRNAs from genomic sequences of viruses, parasites and animals. We have also engaged in the regulation features of human miRNAs in oncogenesis and their cancer biomarker potential in liquid biopsy. There are several bioinformatic databases established in our laboratory:

TPSDG:
https://tpsdg.ibms.sinica.edu.tw

HPSV:
https://hpsv.ibms.sinica.edu.tw
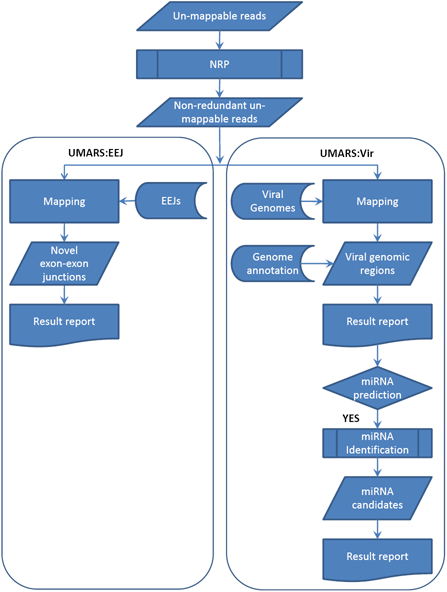
TEx-MST:
https://texmst.ibms.sinica.edu.tw
RTTPG:
https://rttpg.ibms.sinica.edu.tw
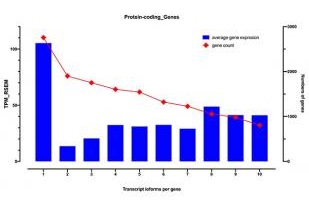
TREGT:
https://tregt.ibms.sinica.edu.tw
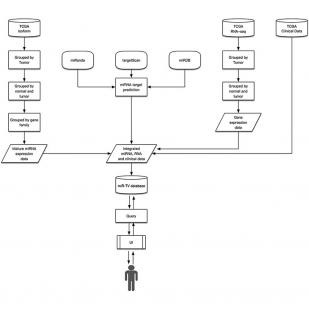
miRTV:
https://mirtv.ibms.sinica.edu.tw
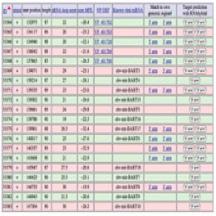
Vir-Mir:
https://alk.ibms.sinica.edu.tw
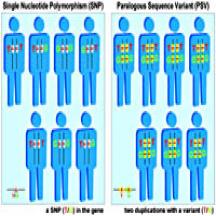
dbDNV:
https://goods.ibms.sinica.edu.tw/DNVs/
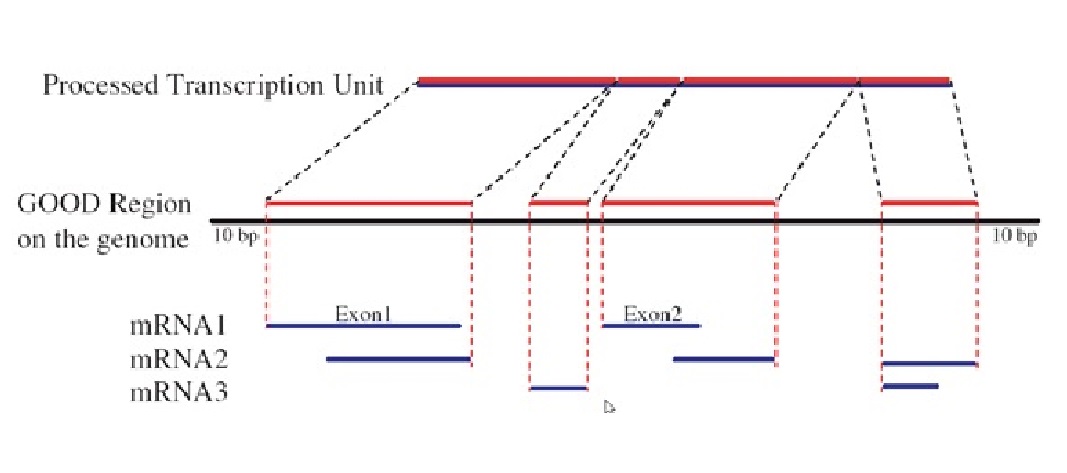
GOOD:
https://goods.ibms.sinica.edu.tw/goods/
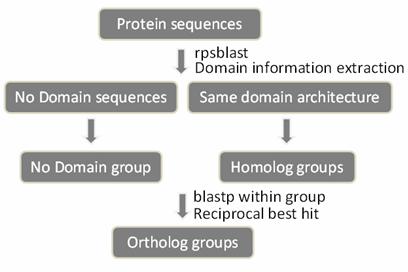
DODO:
https://tdl.ibms.sinica.edu.tw/dodo_web/home.htm

CGI:
https://tdl.ibms.sinica.edu.tw/CGI.htm
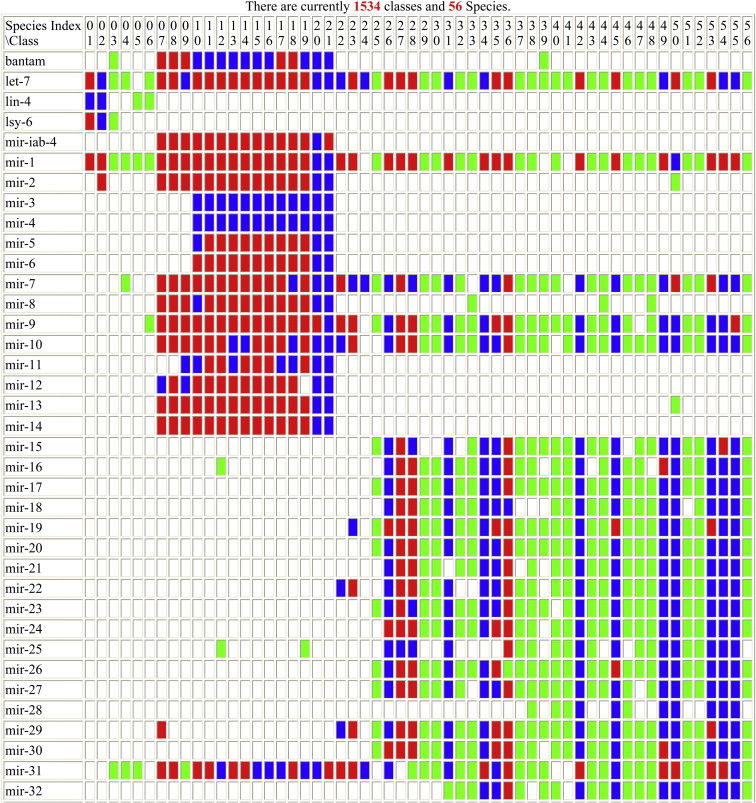
Zoo-Mir:
https://insr.ibms.sinica.edu.tw