| usage of DODO
|
|
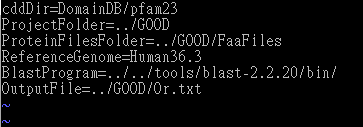
DODO takes protein sequences as input. The protein sequences should be prepared in FASTA format and separated into different file according to their species. These FASTA files should be named as "species_name.fasta". After decompressing DODO.tar.gz, there is a file named "Setting.txt".
An example: The output file is a text file separate by tabs and looks like this: The first column is Ortholog group ID given by DODO. There are two kind of ortholog groups. Ortholog group ID having No_DomainInfo as prefix are ortholog groups of no domain protein sequences identified solely from reciprocal best hits. Ortholog group ID starts with PfamArcNu are proteins identified aided by domain information and reciprocal best hits. The second column is the species name (the file names of FASTA files) and the third column is the gene name.
|
|||||||||||
|
|